
小任务:字符串中是否存在关键字符串
在自然语言处理(NLP)任务中,神经网络被广泛应用于处理文本数据和字符串分类。下面是详细讲解:
1. 字符数值化(通过词表):
- 首先,将文本中的字符映射为数值表示。一种直观的方式是将每个字符映射为一个数字,比如a->1, b->2, ..., z->26。这种映射方式可以帮助将文本数据转化为神经网络可以处理的数值形式。
Padding是指在文本序列中添加特定的填充符号(通常是0)使得所有序列达到相同的长度,这样可以确保输入神经网络的文本序列具有统一的维度。

2.使用enbedding层
目的:“abc" --词表--> 0,1,2 --Embedding层--> 3*n的矩阵,n为维度 --> model矩阵
-- 向量化:
每个字符可以被转化为一个向量,使得每个字符都具有相同的维度。例如,字符'a'可以被表示为[0.32618175, 0.20962898, 0.43550067, 0.07120884, 0.58215387],这样每个字符都对应一个固定长度的向量。
整体映射:
将整个文本字符串映射为一个矩阵。例如,对于字符串"abcd",每个字符转化为向量后可以形成一个4*5的矩阵。这个矩阵可以表示整个字符串的数值化信息。
3.pooling池化
对每个特征图进行池化操作,通常是取特征图中的最大值(Max Pooling)或平均值(Average Pooling)等操作,以降低特征图的维度和提取最显著的特征。
3. 神经网络处理
- 将经过数值化和向量化处理的文本数据输入神经网络进行处理。通常会使用线性公式(如w*x + b)将矩阵映射到实数空间,然后通过激活函数(如sigmoid函数)进行归一化处理,将输出限制在0到1之间。
4. 字符串分类
- 神经网络可以通过训练学习文本数据的特征,并用于字符串分类任务。在训练过程中,网络会不断优化权重和偏置,以使得模型能够准确地对不同类别的字符串进行分类。
通过以上步骤,神经网络可以有效处理文本数据并进行字符串分类任务。这种方法在NLP领域中被广泛使用,能够处理各种文本数据并实现准确的分类和预测。
5.核心代码
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
import random
import json
import matplotlib.pyplot as plt
"""
基于pytorch的网络编写
实现一个网络完成一个简单nlp任务
判断文本中是否有某些特定字符出现
"""
class TorchModel(nn.Module):
def __init__(self, vector_dim, sentence_length, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), vector_dim) #embedding层
self.pool = nn.AvgPool1d(sentence_length) # 池化层(采用平均进行降维)
self.classify = nn.Linear(vector_dim, 1) #线性层
self.activation = torch.sigmoid #sigmoid归一化函数
self.loss = nn.functional.mse_loss #loss函数采用均方差损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #(batch_size, sen_len) -> (batch_size, sen_len, vector_dim) 20*6*20
x = x.transpose(1, 2) #(batch_size, sen_len, vector_dim) -> (batch_size, vector_dim, sen_len) 20*20*6
x = self.pool(x) #(batch_size, vector_dim, sen_len)->(batch_size, vector_dim, 1) 20*20
x = x.squeeze() #(batch_size, vector_dim, 1) -> (batch_size, vector_dim) 将张量 x 中维度为1的维度去除,以便后续的计算或操作。
x = self.classify(x) #(batch_size, vector_dim) -> (batch_size, 1) 20*20 20*1 -> 20*1
y_pred = self.activation(x) #(batch_size, 1) -> (batch_size, 1)
if y is not None:
return self.loss(y_pred, y) #预测值和真实值计算损失
else:
return y_pred #输出预测结果
#字符集随便挑了一些字,实际上还可以扩充
#为每个字生成一个标号
#{"a":1, "b":2, "c":3...}
#abc -> [1,2,3]
def build_vocab():
chars = "abcdefghijklmnopqrstuvwxyz" #字符集
vocab = {"pad":0}
for index, char in enumerate(chars):
vocab[char] = index+1 #每个字对应一个序号
vocab['unk'] = len(vocab) #26
return vocab
#随机生成一个样本
#从所有字中选取sentence_length个字
#反之为负样本
def build_sample(vocab, sentence_length):
#随机从字表选取sentence_length个字,可能重复
x = [random.choice(list(vocab.keys())) for _ in range(sentence_length)]
#指定哪些字出现时为正样本
if set("abc") & set(x):
y = 1
#指定字都未出现,则为负样本
else:
y = 0
x = [vocab.get(word, vocab['unk']) for word in x] #将字转换成序号,为了做embedding
return x, y
#建立数据集
#输入需要的样本数量。需要多少生成多少
def build_dataset(sample_length, vocab, sentence_length):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, sentence_length) # 举例:x=[1,2,3,4,5,6] y=1
dataset_x.append(x)
dataset_y.append([y])
return torch.LongTensor(dataset_x), torch.FloatTensor(dataset_y)
#建立模型
def build_model(vocab, char_dim, sentence_length):
model = TorchModel(char_dim, sentence_length, vocab)
return model
#测试代码
#用来测试每轮模型的准确率
def evaluate(model, vocab, sample_length):
model.eval()
x, y = build_dataset(200, vocab, sample_length) #建立200个用于测试的样本
print("本次预测集中共有%d个正样本,%d个负样本"%(sum(y), 200 - sum(y)))
correct, wrong = 0, 0
with torch.no_grad():
y_pred = model(x) #模型预测
for y_p, y_t in zip(y_pred, y): #与真实标签进行对比
if float(y_p) < 0.5 and int(y_t) == 0:
correct += 1 #负样本判断正确
elif float(y_p) >= 0.5 and int(y_t) == 1:
correct += 1 #正样本判断正确
else:
wrong += 1
print("正确预测个数:%d, 正确率:%f"%(correct, correct/(correct+wrong)))
return correct/(correct+wrong)
def main():
#配置参数
epoch_num = 20 #训练轮数
batch_size = 20 #每次训练样本个数
train_sample = 500 #每轮训练总共训练的样本总数
char_dim = 20 #每个字的维度
sentence_length = 6 #样本文本长度
learning_rate = 0.005 #学习率
# 建立字表
vocab = build_vocab()
# 建立模型
model = build_model(vocab, char_dim, sentence_length)
# 选择优化器
optim = torch.optim.Adam(model.parameters(), lr=learning_rate)
log = []
# 训练过程
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, sentence_length) #构造一组训练样本
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
acc = evaluate(model, vocab, sentence_length) #测试本轮模型结果
log.append([acc, np.mean(watch_loss)])
#画图
plt.plot(range(len(log)), [l[0] for l in log], label="acc") #画acc曲线
plt.plot(range(len(log)), [l[1] for l in log], label="loss") #画loss曲线
plt.legend()
plt.show()
#保存模型
torch.save(model.state_dict(), "model.pth")
# 保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
return
#使用训练好的模型做预测
def predict(model_path, vocab_path, input_strings):
char_dim = 20 # 每个字的维度
sentence_length = 6 # 样本文本长度
vocab = json.load(open(vocab_path, "r", encoding="utf8")) #加载字符表
model = build_model(vocab, char_dim, sentence_length) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的权重
x = []
for input_string in input_strings:
x.append([vocab[char] for char in input_string]) #将输入序列化
model.eval() #测试模式
with torch.no_grad(): #不计算梯度
result = model.forward(torch.LongTensor(x)) #模型预测
for i, input_string in enumerate(input_strings):
print("输入:%s, 预测类别:%d, 概率值:%f" % (input_string, round(float(result[i])), result[i])) #打印结果
if __name__ == "__main__":
main()
test_strings = ["fnvfee", "wzsdfg", "rqwdeg", "nakwww"]
predict("model.pth", "vocab.json", test_strings)
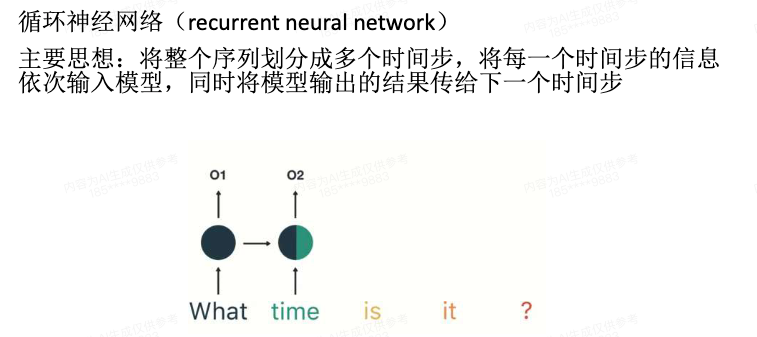
6.引入RNN
假如去求关键字符在字符串中的位置,这就转化为多分类问题,线性层需要构成多维向量,因为是去求在各个位置的概率分布:
 构建数据时,在PyTorch中,onehot编码是通过交叉熵损失函数(CrossEntropyLoss)自动进行的。在定义线性层时,你需要指定类别的数量,在训练模型时,标签数据的维度会自动与最后一层线性层的输出尺寸对齐,即变为一个长度为sentence_length+1的onehot向量。
构建数据时,在PyTorch中,onehot编码是通过交叉熵损失函数(CrossEntropyLoss)自动进行的。在定义线性层时,你需要指定类别的数量,在训练模型时,标签数据的维度会自动与最后一层线性层的输出尺寸对齐,即变为一个长度为sentence_length+1的onehot向量。 因为pooling层没法捕捉顺序信息,所以训练出来后准确率很低,采用rnn可以显著提高准确率:
因为pooling层没法捕捉顺序信息,所以训练出来后准确率很低,采用rnn可以显著提高准确率:
 具体代码:
具体代码:
# coding:utf8
import random
import json
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
"""
基于pytorch框架编写模型训练
实现一个自行构造的找规律(机器学习)任务
输入一个字符串,根据字符a所在位置进行分类
对比rnn和pooling做法
"""
class TorchModel(nn.Module):
def __init__(self, vector_dim, sentence_length, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), vector_dim) #embedding层
# self.pool = nn.AvgPool1d(sentence_length) #池化层
#可以自行尝试切换使用rnn
self.rnn = nn.RNN(vector_dim, vector_dim, batch_first=True)
# +1的原因是可能出现a不存在的情况,那时的真实label在构造数据时设为了sentence_length
self.classify = nn.Linear(vector_dim, sentence_length + 1)
self.loss = nn.functional.cross_entropy
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x)
#使用pooling的情况
# x = x.transpose(1, 2)
# x = self.pool(x)
# x = x.squeeze()
#使用rnn的情况
rnn_out, hidden = self.rnn(x)
x = rnn_out[:, -1, :] #或者写hidden.squeeze()也是可以的,因为rnn的hidden就是最后一个位置的输出
#接线性层做分类
y_pred = self.classify(x)
if y is not None:
return self.loss(y_pred, y) #预测值和真实值计算损失
else:
return y_pred #输出预测结果
#字符集随便挑了一些字,实际上还可以扩充
#为每个字生成一个标号
#{"a":1, "b":2, "c":3...}
#abc -> [1,2,3]
def build_vocab():
chars = "abcdefghijk" #字符集
vocab = {"pad":0}
for index, char in enumerate(chars):
vocab[char] = index+1 #每个字对应一个序号
vocab['unk'] = len(vocab) #26
return vocab
#随机生成一个样本
def build_sample(vocab, sentence_length):
#注意这里用sample,是不放回的采样,每个字母不会重复出现,但是要求字符串长度要小于词表长度
x = random.sample(list(vocab.keys()), sentence_length)
#指定哪些字出现时为正样本
if "a" in x:
y = x.index("a")
else:
y = sentence_length
x = [vocab.get(word, vocab['unk']) for word in x] #将字转换成序号,为了做embedding
return x, y
#建立数据集
#输入需要的样本数量。需要多少生成多少
def build_dataset(sample_length, vocab, sentence_length):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, sentence_length)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)
#建立模型
def build_model(vocab, char_dim, sentence_length):
model = TorchModel(char_dim, sentence_length, vocab)
return model
#测试代码
#用来测试每轮模型的准确率
def evaluate(model, vocab, sample_length):
model.eval()
x, y = build_dataset(200, vocab, sample_length) #建立200个用于测试的样本
print("本次预测集中共有%d个样本"%(len(y)))
correct, wrong = 0, 0
with torch.no_grad():
y_pred = model(x) #模型预测
for y_p, y_t in zip(y_pred, y): #与真实标签进行对比
if int(torch.argmax(y_p)) == int(y_t):
correct += 1
else:
wrong += 1
print("正确预测个数:%d, 正确率:%f"%(correct, correct/(correct+wrong)))
return correct/(correct+wrong)
def main():
#配置参数
epoch_num = 20 #训练轮数
batch_size = 40 #每次训练样本个数
train_sample = 1000 #每轮训练总共训练的样本总数
char_dim = 30 #每个字的维度
sentence_length = 10 #样本文本长度
learning_rate = 0.001 #学习率
# 建立字表
vocab = build_vocab()
# 建立模型
model = build_model(vocab, char_dim, sentence_length)
# 选择优化器
optim = torch.optim.Adam(model.parameters(), lr=learning_rate)
log = []
# 训练过程
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, sentence_length) #构造一组训练样本
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
acc = evaluate(model, vocab, sentence_length) #测试本轮模型结果
log.append([acc, np.mean(watch_loss)])
#画图
plt.plot(range(len(log)), [l[0] for l in log], label="acc") #画acc曲线
plt.plot(range(len(log)), [l[1] for l in log], label="loss") #画loss曲线
plt.legend()
plt.show()
#保存模型
torch.save(model.state_dict(), "model.pth")
# 保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
return
#使用训练好的模型做预测
def predict(model_path, vocab_path, input_strings):
char_dim = 30 # 每个字的维度
sentence_length = 10 # 样本文本长度
vocab = json.load(open(vocab_path, "r", encoding="utf8")) #加载字符表
model = build_model(vocab, char_dim, sentence_length) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的权重
x = []
for input_string in input_strings:
x.append([vocab[char] for char in input_string]) #将输入序列化
model.eval() #测试模式
with torch.no_grad(): #不计算梯度
result = model.forward(torch.LongTensor(x)) #模型预测
for i, input_string in enumerate(input_strings):
print("输入:%s, 预测类别:%s, 概率值:%s" % (input_string, torch.argmax(result[i]), result[i])) #打印结果
if __name__ == "__main__":
main()
test_strings = ["kijabcdefh", "gijkbcdeaf", "gkijadfbec", "kijhdefacb"]
predict("model.pth", "vocab.json", test_strings)