
1.中文分词
1. 分词任务
- 分词是NLP中一类问题的代表
- 分词是NLP任务的基础
2. 中文分词的难点
- 歧义切分
- 新词、专有名词、改造词等
3. 中文分词算法
- 正向最大匹配算法
- 实现方式一:窗口滑动
- 实现方式二:前缀字典
- 反向最大匹配算法
- 双向最大匹配算法
- jieba分词算法
以上缺点:
词表依赖:分词算法过于依赖预先设定的词表,如果词表中缺少某些词,分词结果可能会出错。
语义忽视:分词过程不会考虑整个句子的语义,仅仅依赖词表进行机械切分。
错误影响:文本中的错别字可能会对后续的分词结果产生影响。
未登录词处理:对专有名词、新词等未登录词的识别和处理效果较差。
歧义处理:无法有效处理句子中的歧义。
效果优化空间:当前的分词效果已经比较理想,优化空间不大。
分词影响:分词错误不一定导致下游任务错误,因此花大力气优化分词不一定值得。
预训练模型影响:随着神经网络和预训练模型的兴起,中文任务逐渐不再需要分词,甚至不进行分词效果更好。

2. 基于机器学习的中文分词
- 将分词问题转化为序列标注问题
序列标注其实是每个字符的二分类问题,判断是否为词边界,即针对每个字符预测结构为[-0.9,2],第一个元素代表不是边界的概率分布,第二个元素代表是边界的概率分布
步骤
1.字符数值化向量化,通过字表,embedding层->输入batch的x后->转为shape为(batch_size,sten_len,input_dim)
self.embedding = nn.Embedding(len(vocab) + 1, input_dim, padding_idx=0) #shape=(vocab_size, dim)2.接入rnn层,shape由(batch_size,sten_len,input_dim)—>(batch_size,sten_len,hidden_size)给我的感觉像线性层
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
num_layers=num_rnn_layers,
)3.接入全连接层,shape由(batch_size,sten_len,hidden_size)—>(batch_size,sten_len,2)
self.classify = nn.Linear(hidden_size, 2)4.激活函数:
rnn公式中自带tanh激活函数,可直接使用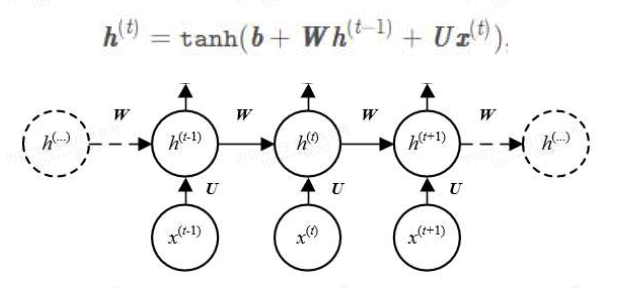 5.损失函数,对于分类问题选择交叉熵损失(Cross Entropy Loss)
5.损失函数,对于分类问题选择交叉熵损失(Cross Entropy Loss)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)因为我们对数据做了padding处理,将文本截断或补齐到固定长度 ,对于补齐的x对应的y值为-100,这里我们就不计算损失
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, label详细代码
#coding:utf8
import torch
import torch.nn as nn
import jieba
import numpy as np
import random
import json
from torch.utils.data import DataLoader
"""
基于pytorch的网络编写一个分词模型
我们使用jieba分词的结果作为训练数据
看看是否可以得到一个效果接近的神经网络模型
"""
class TorchModel(nn.Module):
def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim, padding_idx=0) #shape=(vocab_size, dim)
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
num_layers=num_rnn_layers,
)
self.classify = nn.Linear(hidden_size, 2)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #input shape: (batch_size, sen_len), output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #output shape:(batch_size, sen_len, 2)
if y is not None:
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
class Dataset:
def __init__(self, corpus_path, vocab, max_length):
self.vocab = vocab
self.corpus_path = corpus_path
self.max_length = max_length
self.load()
def load(self):
self.data = []
with open(self.corpus_path, encoding="utf8") as f:
for line in f:
sequence = sentence_to_sequence(line, self.vocab) # 通过此表,字符数值化
label = sequence_to_label(line)
sequence, label = self.padding(sequence, label) # 按照最大字符长度补齐
sequence = torch.LongTensor(sequence)
label = torch.LongTensor(label)
self.data.append([sequence, label])
#使用部分数据做展示,使用全部数据训练时间会相应变长
if len(self.data) > 3000:
break
#将文本截断或补齐到固定长度
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, label
def __len__(self):
return len(self.data)
def __getitem__(self, item):
return self.data[item]
#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):
sequence = [vocab.get(char, vocab['unk']) for char in sentence]
return sequence
#基于结巴生成分级结果的标注
def sequence_to_label(sentence):
words = jieba.lcut(sentence)
label = [0] * len(sentence)
pointer = 0
for word in words:
pointer += len(word)
label[pointer - 1] = 1
return label
#加载字表
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, "r", encoding="utf8") as f:
for index, line in enumerate(f):
char = line.strip()
vocab[char] = index + 1 #每个字对应一个序号
vocab['unk'] = len(vocab) + 1
return vocab
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
def main():
epoch_num = 10 #训练轮数
batch_size = 20 #每次训练样本个数
char_dim = 50 #每个字的维度
hidden_size = 100 #隐含层维度
num_rnn_layers = 3 #rnn层数
max_length = 20 #样本最大长度
learning_rate = 1e-3 #学习率
vocab_path = "chars.txt" #字表文件路径
corpus_path = "corpus.txt" #语料文件路径
vocab = build_vocab(vocab_path) #建立字表
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器
#训练开始
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y in data_loader:
optim.zero_grad() #梯度归零
loss = model.forward(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
#保存模型
torch.save(model.state_dict(), "model.pth")
return
#最终预测
def predict(model_path, vocab_path, input_strings):
#配置保持和训练时一致
char_dim = 50 # 每个字的维度
hidden_size = 100 # 隐含层维度
num_rnn_layers = 3 # rnn层数
vocab = build_vocab(vocab_path) #建立字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重
model.eval()
for input_string in input_strings:
#逐条预测
x = sentence_to_sequence(input_string, vocab)
with torch.no_grad():
result = model.forward(torch.LongTensor([x]))[0]
result = torch.argmax(result, dim=-1) #预测出的01序列
#在预测为1的地方切分,将切分后文本打印出来
for index, p in enumerate(result):
if p == 1:
print(input_string[index], end=" ")
else:
print(input_string[index], end="")
print()
if __name__ == "__main__":
main()
input_strings = ["同时国内有望出台新汽车刺激方案",
"沪胶后市有望延续强势",
"经过两个交易日的强势调整后",
"昨日上海天然橡胶期货价格再度大幅上扬"]
predict("model.pth", "chars.txt", input_strings)
优点:脱离词表,仅需字表即可训练