
kaggle
Kaggle是一个在线数据科学竞赛平台,它聚集了来自世界各地的数据科学家和机器学习爱好者。Kaggle提供各种数据集,用户可以使用这些数据集来练习数据分析和机器学习技能,并通过参与竞赛来解决问题。这些竞赛通常由公司、研究机构或其他组织发起,涉及各种实际问题,如预测房价、识别图片中的物体等。
机器学习初体验
课前学习:https://www.kaggle.com/learn/intro-to-machine-learning
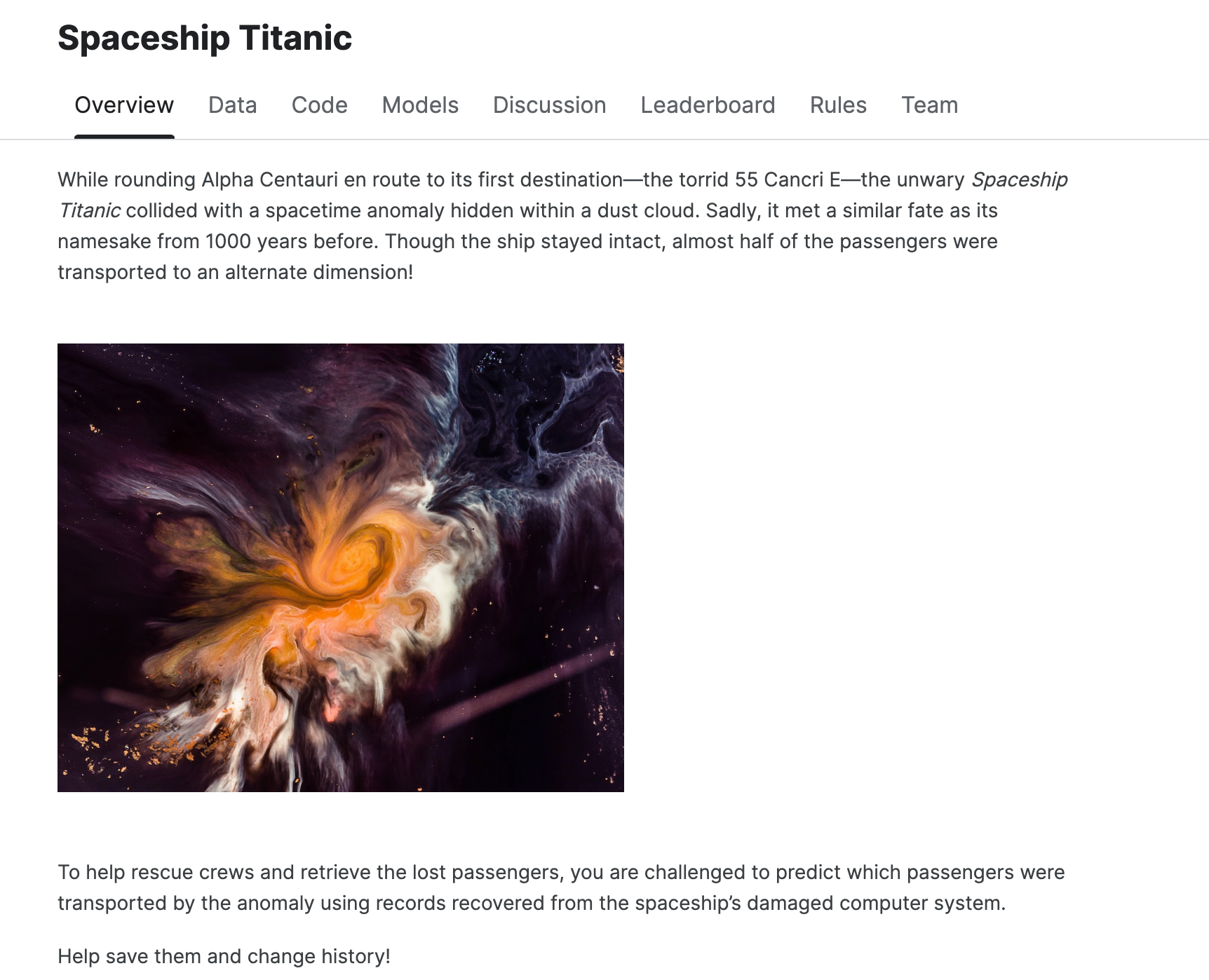
今天我们来参加入门比赛,Spaceship Titanic
比赛是给我们每个乘客数据来预测哪些乘客被异常现象运送。
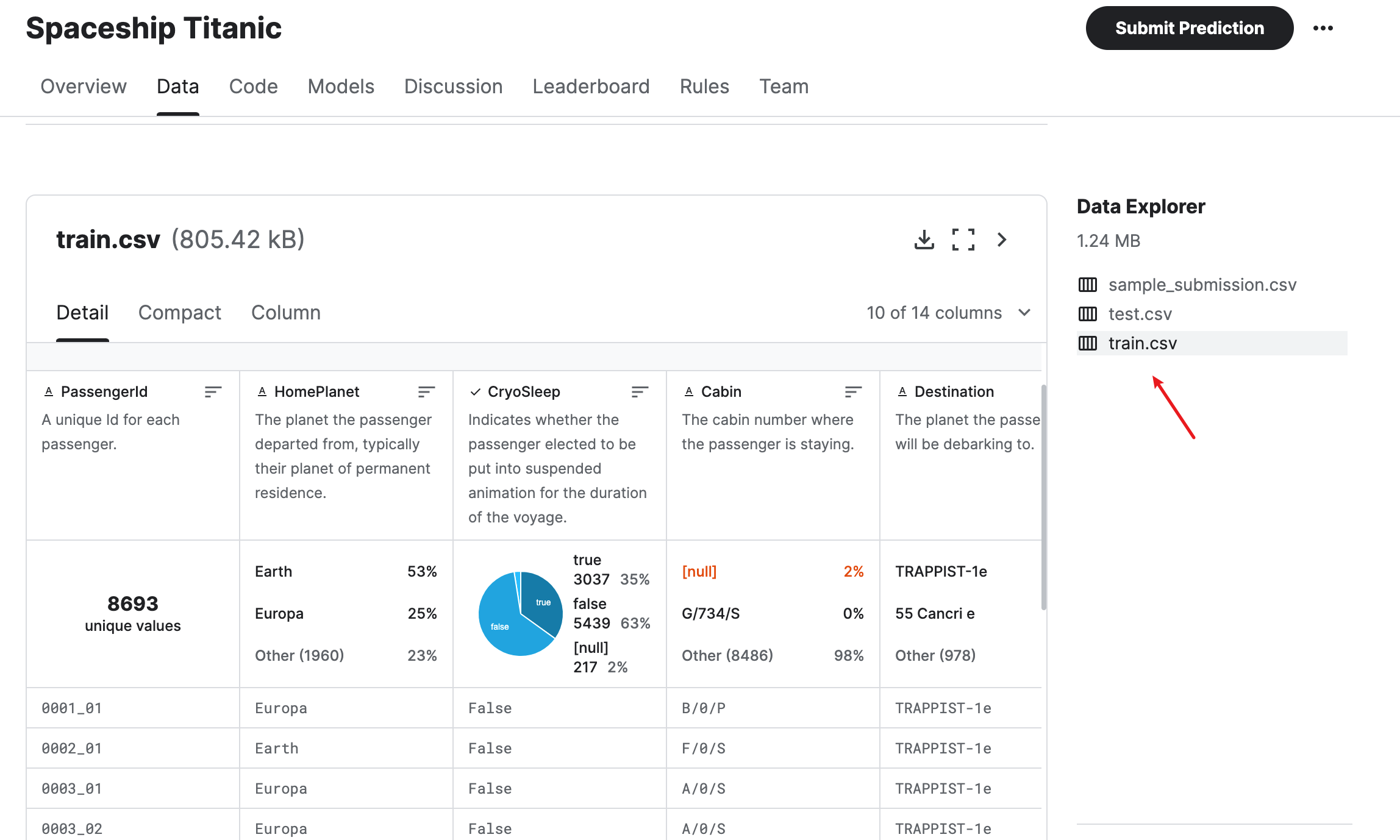
 第一步:数据准备
第一步:数据准备
在正式开始前,我们先熟悉下pandas的一些操作,查看数据
import tensorflow as tf
import tensorflow_decision_forests as tfdf
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
print("TensorFlow v" + tf.__version__)
print("TensorFlow Decision Forests v" + tfdf.__version__)
# Load a dataset into a Pandas Dataframe
dataset_df = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')
print("Full train dataset shape is {}".format(dataset_df.shape))
# Display the first 5 examples
dataset_df.head(5)
# quickly do a basic exploration of the dataset
# count: 非空值的数量(Non-missing values count)
# mean: 平均值(Mean)
# std: 标准差(Standard deviation)
# min: 最小值(Minimum)
# 25% / Q1: 第一四分位数(First Quartile)
# 50% / median: 中位数(Median)
# 75% / Q3: 第三四分位数(Third Quartile)
# max: 最大值(Maximum)
# 数据集的统计摘要
dataset_df.describe()
# 此函数用于展示DataFrame数据集的概要信息
# 打印出数据集中每列的名称、数据类型、非空值数量,以及索引的起始和结束值。
dataset_df.info()
# Bar chart for label column: Transported
plot_df = dataset_df.Transported.value_counts()
plot_df.plot(kind="bar")
# Numerical data distribution¶
# 数值数据分布
fig, ax = plt.subplots(5,1, figsize=(10, 10))
plt.subplots_adjust(top = 2)
sns.histplot(dataset_df['Age'], color='b', bins=50, ax=ax[0]);
sns.histplot(dataset_df['FoodCourt'], color='b', bins=50, ax=ax[1]);
sns.histplot(dataset_df['ShoppingMall'], color='b', bins=50, ax=ax[2]);
sns.histplot(dataset_df['Spa'], color='b', bins=50, ax=ax[3]);
sns.histplot(dataset_df['VRDeck'], color='b', bins=50, ax=ax[4]);下面我们正式开始,首先我们需要将train数据进行预处理,对tfdf不支持的格式我们要进行格式转换,删除无关列,对多值做切分,对缺失值做填充,然后分为80%训练数据集和20%验证数据集,最后对数据格式做转换
#### 1.Prepare the dataset
# 将删除 PassengerId 和 Name 列,因为它们对于模型训练不是必需的。
dataset_df = dataset_df.drop(['PassengerId', 'Name'], axis=1)
dataset_df.head(5)
# 计算DataFrame dataset_df 中每个列的空值数量,并按照空值数量降序排序
dataset_df.isnull().sum().sort_values(ascending=False)
# 用0填充dataset_df数据框中['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
# 这些列中所有的缺失值(NaN值)。它通过调用fillna()函数并传递value=0参数来实现。
dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']] = dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']].fillna(value=0)
dataset_df.isnull().sum().sort_values(ascending=False)
# 由于 TF-DF 无法处理布尔列,因此我们必须调整 Transported 列中的标签,将它们转换为 TF-DF 期望的整数格式。
label = "Transported"
dataset_df[label] = dataset_df[label].astype(int)
# 我们还将布尔字段 CryoSleep 和 VIP 转换为 int。
dataset_df['VIP'] = dataset_df['VIP'].astype(int)
dataset_df['CryoSleep'] = dataset_df['CryoSleep'].astype(int)
# Cabin 列的值是格式为 Deck/Cabin_num/Side 的字符串。
# 在这里,我们将拆分 Cabin 列并创建 3 个新列 Deck 、 Cabin_num 和 Side ,因为这样会更容易训练对这些个人数据进行建模。
dataset_df[["Deck", "Cabin_num", "Side"]] = dataset_df["Cabin"].str.split("/", expand=True)
# 从数据集中删除原始 Cabin 列,因为不再需要它。
try:
dataset_df = dataset_df.drop('Cabin', axis=1)
except KeyError:
print("Field does not exist")
dataset_df.head(5)
# 将数据集分为训练数据集和测试数据集
def split_dataset(dataset, test_ratio=0.20):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples in testing.".format(
len(train_ds_pd), len(valid_ds_pd)))
train_ds_pd.head()
# 在训练模型之前还需要执行一个步骤。
# 我们需要将数据集从 Pandas 格式 ( pd.DataFrame ) 转换为 TensorFlow 数据集格式 ( tf.data.Dataset )
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label=label)第二步:模型及训练
TensorFlow Decision Forests中的基线随机森林模型适用于各种表格型数据集上的监督学习任务,特别是当数据集中存在高维度、复杂关联以及噪声等问题时,该模型因其鲁棒性和解释性而成为一种实用的选择。
关于tfdf详细,可查看官方文档:https://www.tensorflow.org/decision_forests/api_docs/python/tfdf/keras/RandomForestModel
tfdf.keras.get_all_models()
# 有多种基于树的模型供您选择。
# RandomForestModel 随机森林模型
# GradientBoostedTreesModel 梯度提升树模型
# CartModel 购物车模型
# DistributedGradientBoostedTreesModel 分布式梯度提升树模型
# 首先,我们将使用随机森林。这是最著名的决策森林训练算法。
rf = tfdf.keras.RandomForestModel()
rf.compile(metrics=["accuracy"]) #指定了评估指标为准确率(accuracy)。
# 使用单线训练模型
rf.fit(x=train_ds)
#基于树的模型的好处之一是我们可以轻松地将它们可视化。随机森林中使用的默认树数为 300。我们可以选择一棵树在下面显示。
tfdf.model_plotter.plot_model_in_colab(rf, tree_idx=0, max_depth=3)
#横坐标为树的数量,纵坐标为出包准确率(out-of-bag accuracy),最后展示该折线图
import matplotlib.pyplot as plt
logs = rf.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy (out-of-bag)")
plt.show()
# 该代码片段是使用Robot Framework(RF)的API创建一个测试结果检查器对象,并调用其evaluation()方法。
# 这段代码的作用是检查测试结果,获取评估信息。
inspector = rf.make_inspector()
inspector.evaluation()
# 模型进行评估
evaluation = rf.evaluate(x=valid_ds,return_dict=True)
print(evaluation)这里我们还可以查看变量重要性
# 变量重要性通常表示特征对模型预测或质量的贡献程度。
# 使用 TensorFlow 决策森林有多种方法可以识别重要特征。让我们列出决策树可用的 Variable Importances
for importance in inspector.variable_importances().keys():
print("\t", importance)
# NUM_NODES:可能表示决策树模型中作为分裂节点的次数,数量越多说明该特征在构建模型时起到的作用越大。
# SUM_SCORE:可能是特征在所有树结构中累计的得分或权重,用于衡量特征对模型整体性能的贡献度。
# NUM_AS_ROOT:明确指向特征作为决策树根节点出现的次数,这个值越高,说明特征在划分数据集和决定最终输出时的重要性越显著。
# INV_MEAN_MIN_DEPTH:可能是特征首次出现在决策树路径上的平均深度的倒数,深度越浅,说明特征越早被用来进行决策,从而可能反映其在分类或回归任务中的早期影响力。
inspector.variable_importances()["NUM_AS_ROOT"]
# [("CryoSleep" (1; #2), 112.0),
# ("RoomService" (1; #7), 74.0),
# ("Spa" (1; #10), 55.0),
# ("VRDeck" (1; #12), 28.0),
# ("ShoppingMall" (1; #8), 16.0),
# ("FoodCourt" (1; #5), 12.0),
# ("Deck" (4; #3), 2.0),
# ("HomePlanet" (4; #6), 1.0)]第三步:提交答案
### 3.提交答案
# Load the test dataset
test_df = pd.read_csv('/kaggle/input/spaceship-titanic/test.csv')
submission_id = test_df.PassengerId
# Replace NaN values with zero
test_df[['VIP', 'CryoSleep']] = test_df[['VIP', 'CryoSleep']].fillna(value=0)
# Creating New Features - Deck, Cabin_num and Side from the column Cabin and remove Cabin
test_df[["Deck", "Cabin_num", "Side"]] = test_df["Cabin"].str.split("/", expand=True)
test_df = test_df.drop('Cabin', axis=1)
# Convert boolean to 1's and 0's
test_df['VIP'] = test_df['VIP'].astype(int)
test_df['CryoSleep'] = test_df['CryoSleep'].astype(int)
# Convert pd dataframe to tf dataset
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df)
# Get the predictions for testdata
predictions = rf.predict(test_ds)
n_predictions = (predictions > 0.5).astype(bool)
output = pd.DataFrame({'PassengerId': submission_id,
'Transported': n_predictions.squeeze()})
output.head()
sample_submission_df = pd.read_csv('/kaggle/input/spaceship-titanic/sample_submission.csv')
sample_submission_df['Transported'] = n_predictions
sample_submission_df.to_csv('/kaggle/working/submission.csv', index=False)
sample_submission_df.head()
我们只需要将测试数据test.csv预测出的结果填入submission.csv即可,submission.csv名称不能修改,这是你的成绩判定依据
kaggle提供了非常方便的在线代码的notebook,可以直接运行代码,非常方便
 最后你觉得没什么问题后,就可以提交答案了
最后你觉得没什么问题后,就可以提交答案了
 你也可以看到自己的天梯排名:
你也可以看到自己的天梯排名:
额外补充
MAE
#Mean Absolute Error (also called MAE).
#使用 MAE 指标,我们取每个错误的绝对值。这会将每个错误转换为正数。然后,我们取这些绝对误差的平均值。这是我们对模型质量的衡量标准。
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)过拟合&欠拟合
overfitting:模型几乎完美地匹配了训练数据,但在验证和其他新数据中表现不佳
underfitting:模型无法捕获数据中的重要区别和模式时,即使在训练数据中也表现不佳,这称为欠拟合。
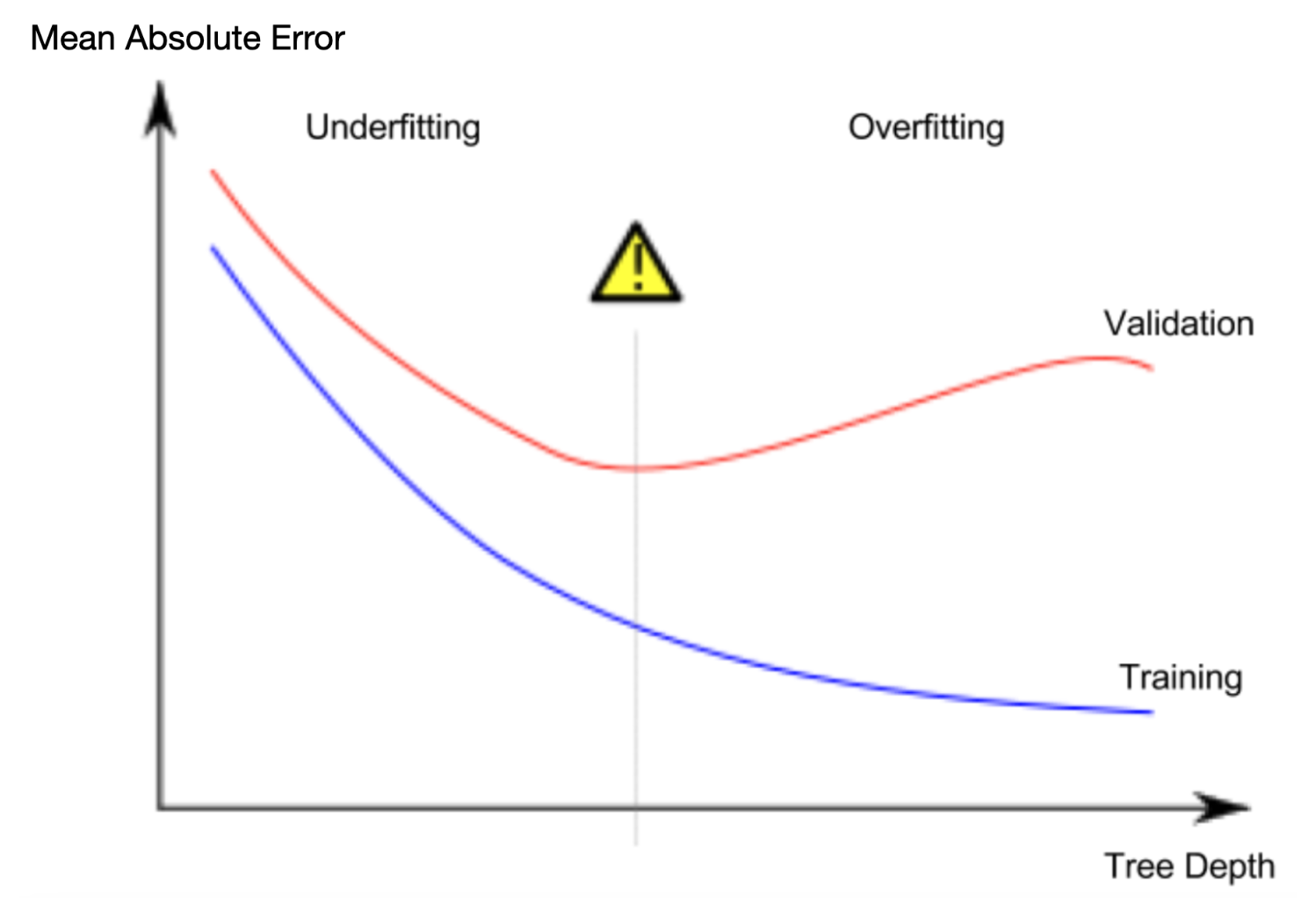 由于我们关心新数据的准确性,这是我们根据验证数据估计的,因此我们希望找到欠拟合和过拟合之间的最佳点。从视觉上看,我们想要下图中(红色)验证曲线的低点。
由于我们关心新数据的准确性,这是我们根据验证数据估计的,因此我们希望找到欠拟合和过拟合之间的最佳点。从视觉上看,我们想要下图中(红色)验证曲线的低点。
控制树的深度有几种替代方法,许多方法允许通过树的某些路径比其他路径具有更大的深度。但是max_leaf_nodes的论点提供了一种非常明智的方法来控制过拟合与欠拟合。我们允许模型制作的叶子越多,我们从上图中的欠拟合区域移动到过拟合区域的次数就越多。
我们可以使用效用函数来帮助比较不同值的 MAE 分数,max_leaf_nodes:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))