
如何增强模型能力
微调是其中的一个方法,当然还有其他方式,比如外挂知识库或者通过 Agent 调用其他 API 数据源,下面我详细介绍下这几种方式的区别。
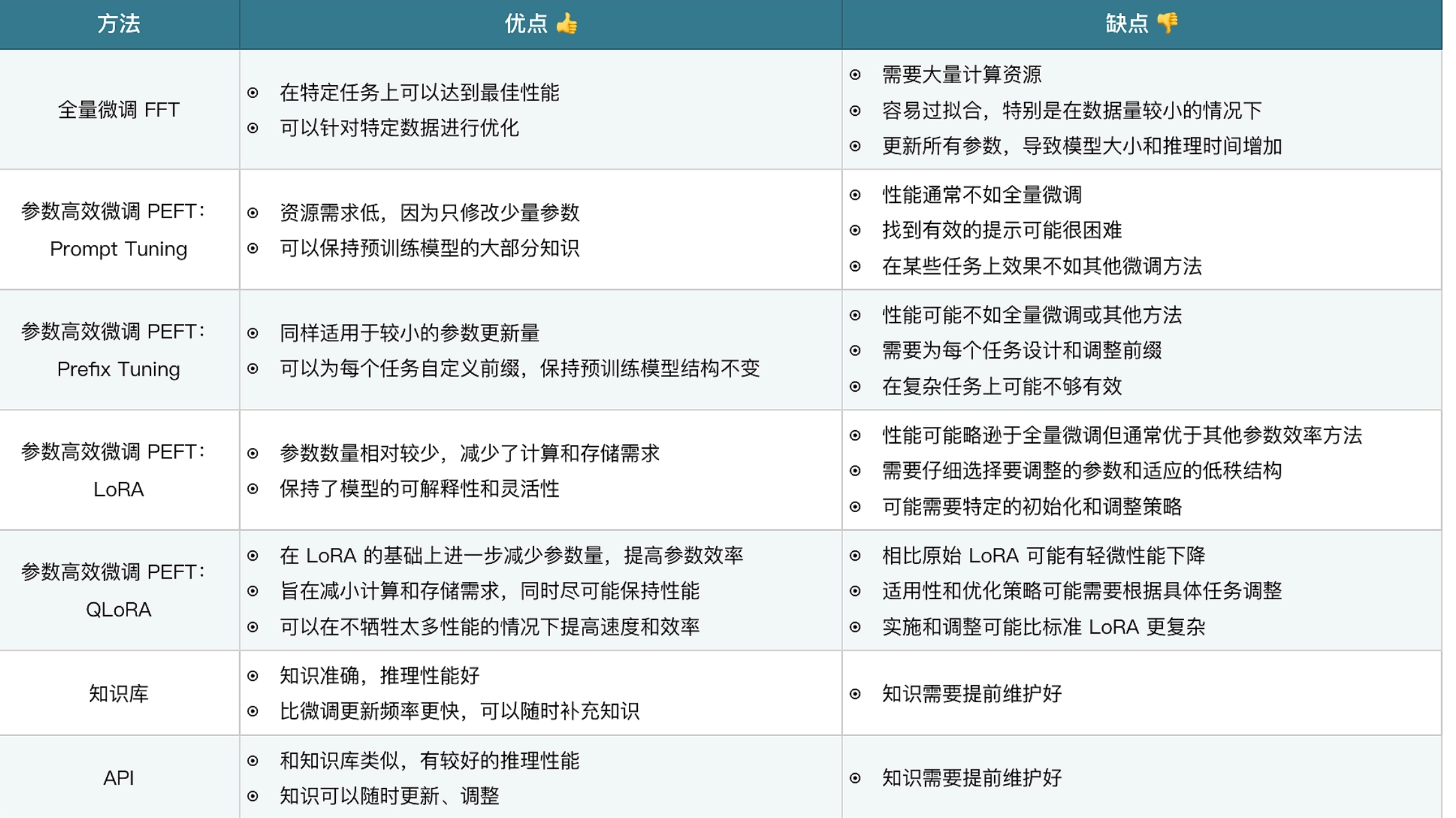
微调是一种让预先训练好的模型适应特定任务或数据集的方案,成本相对较低,这种情况下,模型会学习训练者提供的微调数据,并且具备一定的理解能力。
知识库使用向量数据库或者其他数据库存储数据,为大语言模型提供信息来源外挂。
API 和知识库类似,为大语言模型提供信息来源外挂。
简单理解,微调相当于让大模型去学习一门新的学科,在回答的时候进行闭卷考试,知识库和 API 相当于为大模型提供了新学科的课本,回答的时候进行开卷考试。几种模式并不冲突,可以同时使用几种方案来优化模型,提升内容输出能力,下面我简单介绍下几种模式的优缺点。
在大模型实际落地过程中,我们需要先分析需求,然后确定落地方式。
微调:准备数据、微调、验证、提供服务。
知识库:准备数据、构建向量库、构建智能体、提供服务。
API:准备数据、开发接口、构建智能体、提供服务。
Lora实战
下面我就举个Lora微调ASR语音识别模型whisper的例子带你深入理解:
我们将使用几个流行的 Python 包来微调 Whisper 模型。我们将用于 datasets 下载和准备我们的训练数据,并 transformers 加载和训练我们的 Whisper 模型。我们还需要该 librosa 包对音频文件进行预处理, evaluate 并 jiwer 评估模型的性能。最后,我们将使用 PEFT 、 bitsandbytes accelerate 来准备和微调 LoRA 模型。
加载数据集
使用🤗数据集,下载和准备数据非常简单。我们可以在一行代码中下载和准备 Common Voice 拆分。首先,确保你已接受 Hugging Face Hub 上的使用条款:mozilla-foundation/common_voice_13_0。
由于印地语的资源非常匮乏,我们将合并 train 和 validation 拆分以提供大约 12 小时的训练数据。我们将使用 6 小时 test 的数据作为我们的保留测试集:
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
language_abbr = "hi" # Replace with the language ID of your choice here!
common_voice["train"] = load_dataset(dataset_name, language_abbr, split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset(dataset_name, language_abbr, split="test", use_auth_token=True)
print(common_voice)大多数 ASR 数据集仅提供输入音频样本 ( audio ) 和相应的转录文本 ( sentence )。Common Voice 包含其他元数据信息,例如 accent locale 和 ,我们可以忽略这些信息。为了尽可能保持笔记本的通用性,我们只考虑输入音频和转录文本进行微调,丢弃额外的元数据信息:
common_voice = common_voice.remove_columns(
["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes", "variant"]
)
print(common_voice)由于我们的输入音频以 48kHz 的频率采样,因此我们需要在将其传递给 Whisper 特征提取器之前将其下采样到 16kHz,16kHz 是 Whisper 模型预期的采样率。
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))准备特征提取器、分词器和数据
ASR 管道可以分解为三个阶段:
A feature extractor which pre-processes the raw audio-inputs
一种功能提取器,用于预处理原始音频输入The model which performs the sequence-to-sequence mapping
执行序列到序列映射的模型A tokenizer which post-processes the model outputs to text format
将模型输出后处理为文本格式的分词器
在 Transformer 中🤗,Whisper 模型有一个关联的特征提取器和分词器,分别称为 WhisperFeatureExtractor 和 WhisperTokenizer
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained(model_name_or_path)
from transformers import WhisperTokenizer
task = "transcribe"
tokenizer = WhisperTokenizer.from_pretrained(model_name_or_path, language=language_abbr, task=task)
# 为了简化特征提取器和分词器的使用,我们可以将两者包装到一个 WhisperProcessor 类中。
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained(model_name_or_path, language=language, task=task)准备数据
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=2)训练与评估
评估指标:在评估过程中,我们希望使用单词错误率 (WER) 指标来评估模型。
import evaluate
metric = evaluate.load("wer")import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch为了减少模型的内存占用,我们以 8 位加载模型
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained(model_name_or_path, load_in_8bit=True, device_map="auto")from peft import prepare_model_for_int8_training
model = prepare_model_for_int8_training(model, output_embedding_layer_name="proj_out")def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.model.encoder.conv1.register_forward_hook(make_inputs_require_grad)将低秩适配器 (LoRA) 应用于模型
from peft import LoraConfig, PeftModel, LoraModel, LoraConfig, get_peft_model
config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
model = get_peft_model(model, config)
model.print_trainable_parameters()定义训练配置
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="reach-vb/test", # change to a repo name of your choice
per_device_train_batch_size=8,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-3,
warmup_steps=50,
num_train_epochs=3,
evaluation_strategy="steps",
fp16=True,
per_device_eval_batch_size=8,
generation_max_length=128,
logging_steps=100,
# max_steps=100, # only for testing purposes, remove this from your final run :)
remove_unused_columns=False, # required as the PeftModel forward doesn't have the signature of the wrapped model's forward
label_names=["labels"], # same reason as above
)from transformers import Seq2SeqTrainer, TrainerCallback, TrainingArguments, TrainerState, TrainerControl
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
# This callback helps to save only the adapter weights and remove the base model weights.
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
kwargs["model"].save_pretrained(peft_model_path)
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
if os.path.exists(pytorch_model_path):
os.remove(pytorch_model_path)
return control
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
tokenizer=processor.feature_extractor,
callbacks=[SavePeftModelCallback],
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!trainer.train()
微调模型大约需要 6-8 小时。
基于fast-whisper 我们可以将模型进行CTranslate2,提高速度